HASHING
Hashing: It is an effective search technique used to locate an element with search key value or an index. We begin with a hash function that takes a key and maps it to some index in the array. If all the keys are mapped to different index then there is no problem. But, if several keys maps to the same index, a collision occurs which must be handled. Hashing provides a very fast access to records on search conditions. Hashing is used to provide a function called hash function, that is applied to a given key element to yield the address of the disk block in which it is to be stored.
Hashing may be either internal or external. Internal hashing applicable on internal files may be implemented as ranging from 0 to (n-1). We, then, chose a hash function that transforms the hash key field into an integer between 0 and (n-1). Hashing for disk files is called external hashing. Buckets (or memory location) are used to store more key elements. Each bucket contains one or more records. The hashing function maps a key into a relative bucket number. The collision chances are fewer since one or more key elements may be assigned to a bucket without any problem.
A hash function that maintains the records in the order of hash field values is called order preserving hash function. If the number of buckets/hash addresss space is fixed, the hashing technique is called static hashing. Thus, it is quite difficult to expand the table to accommodate more entries. In such a case, dynamic hashing schemes may be used that allow dynamic expansion and shrinking during run time. Extensible hashing is a dynamic hashing technique. In extensible hashing, additional buckets may be allocated dynamically as and when needed. Thus, the performance does not degrade with the increase in size.
Hash Table: The hash table or the lookup table contains two entries {key, index}. All the key indexes are initialized with zero. Hash table is used to store key elements such that the time taken for retrieval of any key is minimal as compared to other data structures, say linked list, stacks, queues, graphs etc. A hash function is required to hash/position the given key element in the hash table, such that locating that key element is almost instant provided we have defined an efficient hash function. The size of the hash table is predefined such that mapping of key elements to a hash table is done in the predefined limit. Hash function may consider the size of the hash table to generate the hash key to position the key element in the hash table. A hash function is considered to be good if it results in no or minimum collisions. Hashing may be used for indexing key elements or records to facilitate quick retrieval of data. A hash table contains a key value and an index, where index value specifies the state of the memory location i.e. whether it already contains a key element or is empty. Any flag may be used with values 0 or 1, where 0 indicates the position is empty and 1 indicates that it contains a key element. If a collision occurs i.e. more than one key value maps to the same index, collision resolution techniques are adopted for resolving collisions.
A hash function is considered to be an efficient hash function if it maps all or most of the keys to distinct locations.
Consider the following example:
25, 17, 19, 21, 18, 35, 38, 14
The hash function may be defined as follows:
int h(key)
{return (key%n);
}
where n is an integer, may be considered as 10. The hash table of size 10 for the above given integers may be defined as follows:
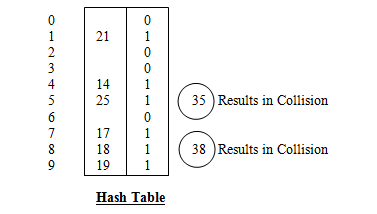
As per the given hash function, key element 35 should be inserted at index 5, but key index 5 is already 1 i.e. it occupies a valid key element, such a situation is called collision, which must be resolved. Similarly insertion of key 38 results in collision, since index 8 is already filled with 18 key value.
Methods to Define Hash Functions:
- Division Method
- Truncation
- Folding
- Mid-Square Method
- Multiplication Method
- Radix Transformation
- Digit Rearrangement
1. Division Method: The given number is divided by an integer, that is usually considered to be the size of the hash table or lookup table. The remainder so obtained as a result of division is the hash key where this key element may be mapped in the table. Thus, if the hash table contains ten index entries from 0 to 9, the given integer may be divided by 10 to obtain the hash key for mapping that element in the hash table.
2. Truncation: Ignore a part of the key and use the remaining part directly as the index say for example, if a hash table contains 999 entries at the most or 999 different key indexes may be kept, then a hash function may be defined such that from an eight digit integer 12345678, first, second and fifth digits from the right may be used to define a key index i.e. 478, which is the key position in the hash lookup table where this element will be inserted. Any other key combination may be used.
3. Folding: Partition the key into several parts and combine the parts in a convenient way (often addition or multiplication) to obtain the index. Say for example an eight digit integer can be divided into groups of three, three and two digits (or any other combination) the groups added together and truncated if necessary to be in the proper range of indices. Hence 12345678 maps to 123+456+78 = 657, since any digit can affect the index, it offers a wide distribution of key values.
4. Mid-Square Method: In Mid-Square method, the key element is multiplied by itself to yield the square of the given key. If the hash table contains maximum 999 entries, then three digits from the result of square may be chosen as a hash key for mapping the key element in the lookup table. It generates random sequences of hash keys, which are generally key dependent. Mid Square method is a flexible method of selecting the hash key value.
5. Multiplication Method: For mapping a given key element in the hash table, individual digits of the key are multiplied. the result so obtained is divided by an integer, usually taken to be the size of the hash table to obtain the remainder as the hash key to place that element in the lookup table.
6. Radix Transformation Method: Where the value or key is digital, the number base (or radix) can be changed resulting in a different sequence of digits. For example: A decimal numbered key could be transformed into a hexadecimal numbered key. High order digits could be discarded to fit a hash value of uniform length.
7. Digit Rearrangement: This is simple taking part of the original value or key such as digits in position 3 through 6, reversing their order and then using that sequence of digits as the hash value or key.
Collision Resolution: If more than one key elements maps to the same index in the hash table, a collision is said to occur, and to resolve this collision, we may prefer using methods mentioned below:
- Linear Probing
- Quadratic Probing
- Random Probing
- Clustering
- Increment Functions/Rehashing/Double hashing
- Key Dependent Increments
- Collision Resolution by Chaining
- Coalesced Chaining
Linear Probing: If a collision occurs, we may perform a sequential search for the desired key or an empty location. Say for example: 14, 39, 11, 24
The hash function may be defined as-
int hash(int key)
{return (key%10);
}

This method searches for a vacant index in straight line from the mapped index that results in collision, hence it is called linear probing. The array may be considered circular for efficiency.
Quadratic Probing: If there is a collision at hash address h, this method probes the table at locations h+1, h+4, h+9…….. and so on i.e. at location h+i2, for i=1,2,3………… i.e. the increment function is i2.
Random Probing: A pseudorandom number generator may be used to obtain the increment. Thus a random number so generated defines the new index in the hash table to map a given key element such that the collision may be avoided.
Clustering: The Linear Probing method places the elements in a sequence, thus finding an empty location becomes time consuming as most of the key values get clustered together. If a few keys happen randomly to be near each other, then it becomes more and more likely that other keys will join them and the distribution will become progressively more unbalanced. Thus clustering occurs on account of placing elements in a sequence in case of collision, which must be avoided for proper arrangement of key elements in the hash table.
Increment Functions: To prevent clustering, re-hashing or double hashing may be used. If by using one hash function, collision occurs, then another hash function may be considered to obtain the result. (a vacant index in the hash table). This process of using another hash function to locate a new index in case of collision is called re-hashing or double hashing technique and is quite useful for arrangement of key elements at unique position.
Key-dependent Increments: We may truncate the key to a single digit and use it as an increment, say for the number 12345, the key may be defined as 123+45 i.e. 168 and if collision occurs at this index, then out of 12345, any digit say 5 may be used as an increment to the index i.e. 168+5=173 will be the new index, where the key may be placed in the hash table.
Collision Resolution by Chaining: It involves linking the key element at the end of the key element at the index where collision occurs. Thus, it may easily be implement by way of linked list where each index is a chain or linked list of various nodes combined together by means of address of the next node. An example given below illustrates the concept:
The following hash function may be considered:
int hash(int key)
{return (key/10);
}
For example: 45, 68, 15, 95, 86, 27, 55, 65, 84, 24, 59, 52

A Chained Hash Table
Coalesced Chaining: In this method, the key elements that take the same position in the hash table are linked together for easy retrieval and easy addition of new key elements. It is similar to linear probing, in which the keys mapped to the same hash address are placed at subsequent vacant address in the hash table, which are linked together in case of coalesced chaining. These links may be maintained via. storing address using pointers. When a new key element is to be inserted in a hash table, if an empty location is found, then the key is mapped at their address, otherwise the chain is traversed to locate next expty index for inserting the key element. This method of insertion of a key element in a hash table is termed as coalesced chaining.
Ques. Program to define a hash table/lookup table, which is used to retrieve values required by the user. Assume the numbers to be stored in the hash table to be of two digits, handled by this hash function for the sake of simplicity.
Solution:
#include <iostream.h>
#include <conio.h>
#include <stdlib.h>
#define MAX 10
void hash_table(int arr[][2],int num,int pos);
int hashfunc(int num);
void hash_table(int arr[][2],int num,int pos)
{if(arr[pos][1]==1)
{cout<<“Collision at index “<<pos;
exit(1);
}
arr[pos][0]=num;
arr[pos][1]=1;
}
int hashfunc(int num)
{return (num%10);
}
void main()
{
clrscr();
int hash[MAX][2],arr[MAX];
int i,j,pos;
for(i=0;i<MAX;i++)
hash[i][1]=0;
for(i=0;i<MAX;i++)
{cout<<“Enter value?”;
cin>>arr[i];
pos=hashfunc(arr[i]);
hash_table(hash,arr[i],pos);
}
int num;
cout<<“Enter the number you wish to search?”;
cin>>num;
pos=hashfunc(num);
if(hash[pos][1]==1)
{if(hash[pos][0]==num)
cout<<“Number found…!”<<hash[pos][0];
}
else
{cout<<“Number does not exist…!”;
}
getch();
}
Symbol Tables: A symbol table is merely a table with two fields, a name field and an information field. We need to be able to do the following jobs with a symbol table.
- determine whether a given name is in the table.
- add a new name to the table.
- access the information associated with a given name, and
- add new information for a given name.
- delete a name or group of name from the table.
The three symbol table mechanisms are linear list, trees and hash tables. We shall evaluate each scheme on the basis of the requirement to add n entries and make m inquiries.
- A linear list is the simplest scheme to implement, but the proformance becomes poor when m and n get large.
- A binary search tree gives better performance at some increase in implementation difficulty.
- Hashing schemes provide the best performance for somewhat greater programming effort and some extra space.
To implement a symbol table, the data structures used are linear lists, hash tables and various sorts of tree structures. A issue is the speed with which an entry can be added or accessed. A linear list is slow to access but simple to implement. A hash table is fast but more complex. Tree structures given intermediate performance.
Symbol table structure:
Data
Information
—————
Data Information
—-
—-
—-
—-
N
To appreciate the level of detail that goes into the symbol table contents, let us consider the data that can be associated with a name in the symbol. This information includes:
- The string of characters denoting the name.
- Attributes of the name(the attributes of a name determine its properties). The most important attribute of a name is its type, which determines what values it may have, possibly the way its value is to be represented in computer, and the operations to which it may be subjected. Other attributes of a name may determine its scope, that is, when its value is accessible.
- Parameters such as the number of dimensions of arrays and the upper and lower limits along each dimension.
- An offset describing the position in storage to be allocated for the same.
The structure of the symbol table may be declared as follows:
struct symboltable
{
char *name; /*name of the object*/
int size; /*size of name field*/
char type; /*data type*/
struct symboltable *next; /*address to next node*/
struct symboltable *link; /*address to next value*/
}symb;
Tables may be access tables implemented using arrays, triangular tables, jagged tables or hash tables.